高效智算网络解决方案

方案背景
随着各种智能应用的不断涌现,数据量呈爆发式增长,高性能计算从传统的工程科学应用计算慢慢地向大数据计算、机器学习和 AI 运算等新兴数据密集型计算发展。这种趋势不仅对算力提出了新的要求,也对异构算力并行计算的数据同步效率提出了要求,多卡多机是智算平台的基本形态,多机间通信性能成为衡量集群性能的重要指标,更高的数据吞吐、更低的时延和更稳定的 I/O 能力,是有效提升算力的基础。中科驭数基于DPU 产品打造的高性能算力网络解决方案,为智算平台算力芯片之间提供高效稳定的数据通道,有效降低传输时延和算力损耗,让集群网络不再是算力输出的瓶颈。
行业痛点
中断频繁,传输效率低下
传统的数据同步和调度,依赖 CPU 来处理网络请求和内存、显存之间的数据拷贝,这时 CPU 会成为数据I/O 的瓶颈,导致数据在节点间的传输效率低下,进而影响智算平台整体的计算性能。
网络性能瓶颈
受限于网络时延和带宽限制,千亿模型训练时间长达数十天,万卡集群节点间数据同步效率低下,耗费大量算力,扩展能力十分有限。
网络拥塞与负载不均
随着计算任务规模的扩大,网络流量急剧增加,可能导致网络拥塞,会导致丢包和网络传输效率骤减,进而影响整体的计算效率和性能
资源利用率低下
多租户环境下,资源独占隔离,导致GPU显存等资源无法跨任务共享,形成资源孤岛。算力资源负载不均衡,无法得到充分利用,导致成本居高不下。
整体方案
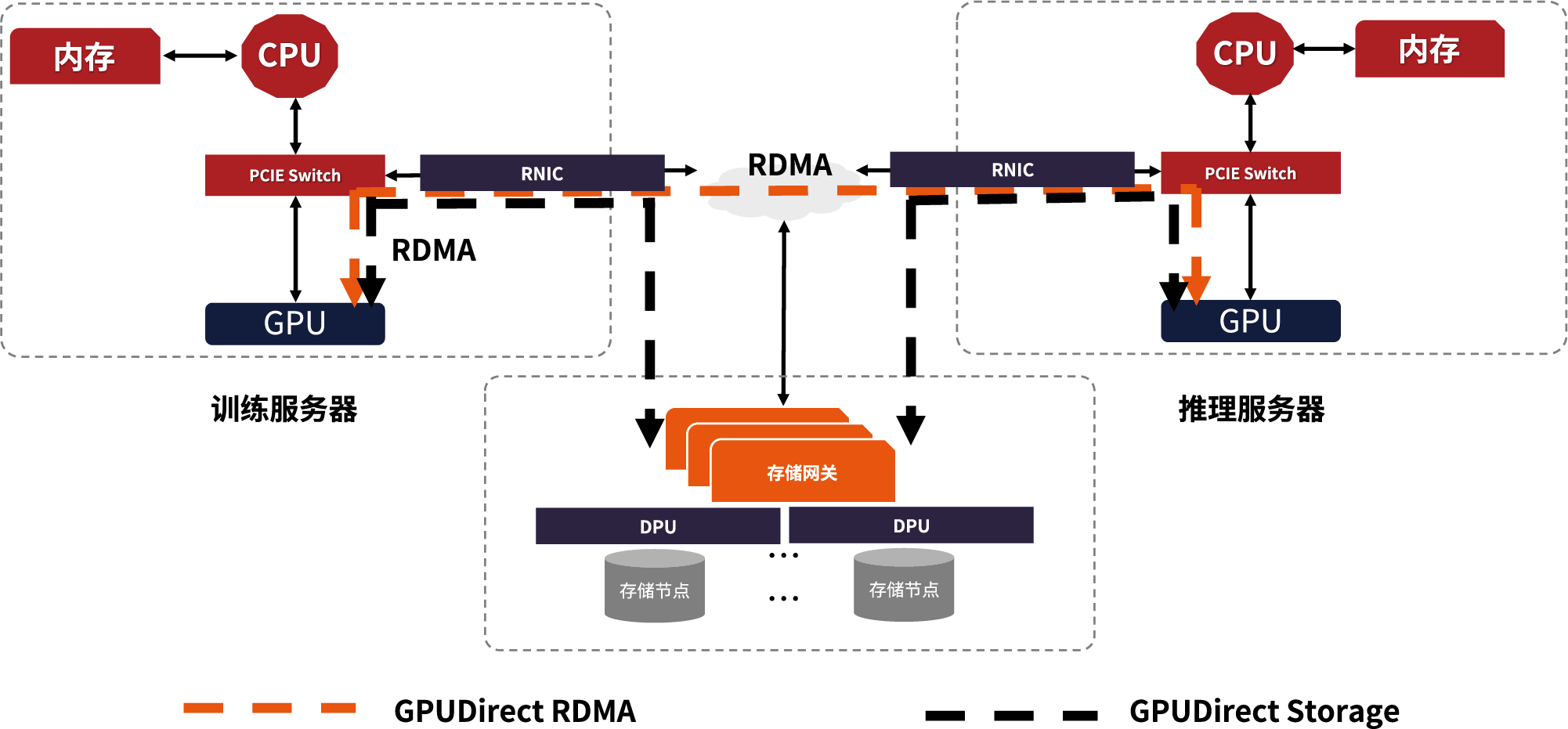
中科驭数高性能智算基础网络解决方案,使用自主研发的 RDMA 网络 DPU 卡产品,构建高吞吐、低时延的 RoCEv2 无损网络,利用 GPUDirect RDMA 技术,在多卡多机的智算平台中实现跨节点的 GPU 显存共享,结合 GPUDirect Storage 技术,实现 AI 服务器之间,算力与存储之间的快速数据通路,提升多点协同效率。同时,利用 DPU 卡的拥塞控制、重传、流量整形等流控技术,实现负载均衡、高效稳定的无损 RDMA 网络。FLEXFLOW 2200R DPU 卡可广泛应用于裸金属、虚拟化、高性能 AI 计算等多种场景,为新型数据密集型高性能计算应用打造高效可靠的基础算力网络。
方案特点
100G高性能RoCEv2网络
基于RoCEv2技术实现微秒级时延和100Gbps带宽的高性能RDMA网络,通过拥塞控制,流量管理等技术实现高效、均衡的无损网络数据传输。支持SR-IOV虚拟化,进一步提高了资源利用率和系统稳定性,为智算算力集群提供性能卓越、稳定可靠的网络环境。
支持GPUDirect技术
通过GPUDirect RDMA(GDR)技术实现高带宽、低时延的P2P数据传输,提高GPU芯片计算效率和资源利用率。支持NCCL、UCX等主流集合通信库,与AI智算生态无缝融合,为GPU服务器应用快速部署提供高效便捷的网络环境
KISA指令集结合微码众核
创新使用微码众核技术结合KISA专用指令集,整体架构兼具灵活性,高性能,强扩展等特点,自主流片设计,全链路自主可控。同时,深度融合国产软硬件生态,适配国产CPU、GPU服务器和操作系统,弥补国内生态在高性能网络方面的不足
自主可控
自主研发的K2-Pro芯片,多项核心专利技术加持,持续保持技术领先
高效运维
丰富的运维管理,硬件实时统计和网卡状态监控功能,支持拥塞控制算法,同时还提供端到端数据包级别的流量控制,QP级精准异常管理,最大程度保证网络稳定
释放CPU算力
支持卸载部分CPU处理逻辑,例如校验和计算、传输层分片重组等,支持内核旁路,数据零拷贝,以减轻CPU负载,释放算力
相关产品

方案价值
随着高性能计算的发展,大数据、机器学习和AI运算等新兴计算技术对数据高速传输能力的依赖性越来越明显。本方案基于驭数自主研发的RDMA DPU产品,具有业界领先的性能水准,可以提供高效可靠的数据通信基础设施,能显著提高智算平台的扩展能力和算力使用效率,降低能耗和资源损耗,填补了国产市场相关领域的产品空白,同时提供更适合国内高性能计算行业的定制化开发灵活性,致力于打造国内高性能计算生态联合解决方案样板。